А8. Грузоперевозки Colgate-Palmolive Company в России
Нужно смоделировать систему распределения между складами в ANylogic не совсем сложную, геоданные есть, количество машин и затраты можно взять за условные единицы, две модели, одна с РЦ в Москве, другая с РЦ в Москве и Новосибирске,

- Нужно две модели одинаковые по своей сути, но с одним важным отличием. Первая с Распред Центром в Москве, другая с РЦ и в Москве и в Новосибирске. Цель — показать, что второй вариант гораздо выгоднее. Как? Взять данные из интернета или принять какую то условную единицу за стоимость и рассчитать издержки на транспорт и на складскую грузопереработку. Чтоб как в прошлогоднем проекте внизу высвечивалась цифра, что вот издержки при этой модели такие то. Самое главное ограничение при моделировании транспорта. Маршруты только по России, а те что ведут во Владивосток и Иркутск перепилить по транссибу, не через Китай, как они по ГИСу идут, а именно по российской территории, то бишь перетянуть точки Маршрутов. Транспортировка тоже только авто, либо найти в инете любую инфу по похожей компании, либо взять условный максимум у РЦ и распределить по региональным складам, куда едет определенное количество авто для того чтобы забрать груз. Возможно вывести в модели отедльную табличку где будет видно, что 90% процентов груза мы перевозим, а 10% груза забирают с РЦ и со складом самовывозом (если возможно)
- Часть данных может быть рассчитана экспертно, часть из интернета у схожих компаний, здесь нет категоричности, что все у Палмолив должны смотреть
- суть показать как работает и что децентрализация гораздо лучше, чем РЦ в Москве далекий от регионов Востока
- если нужны будут поставщики, готовы их предоставить, страны и города откуда везут
Отправить агента агенту
send(order, truck); В агенте truck нужно поставить statechart, чтобы обработать получаемые сообщения.
откуда.moveTo(«куда_широта_долгота») можно сокращенно
moveTo(«куда») , если мы вызываем функцию из самого агента moveTo(getNearestAgent(«популяция_агентов»)) — можно ссылку на агента
ВЫБОР ОТДЕЛЬНОГО ЭЛЕМЕНТА КОЛЛЕКЦИИ ПОПУЛЯЦИИ
top(коллекция, value) — Возвращает элемент с максимальным значением в заданной коллекции.
Пример: Person person = top( people, p ->p.age );
В этом примере мы получаем самый старый элемент коллекции people. Если коллекция пуста, функция вернет null.
List filter(коллекция, условие) — Возвращает подмножество указанной коллекции: новый список элементов, удовлетворяющих заданному условию.
Примеры: List women = filter( people, p ->p.gender == FEMALE );
List idleTrucks = filter( trucks, t -> t.inState(Idle) );
List findAll(коллекция, условие) — Функция, идентичная следующей: filter(коллекция, условие)
findFirst(коллекция, условие) — Возвращает первый элемент указанной коллекции, для которого результат вычисления заданного условия равен true. Возвращает null, если такого элемента нет или коллекция пуста.
Пример: Person person = findFirst( people, p ->p.age > 20 );
ЗАМЕТКИ И СБОР ЦЕННОГО:
Данные взяты из кейса компании «Colgate-Palmolive», предоставленного ВШЭ. Также, некоторые данные получены из открытых источников в интернете и методом экспертной оценки.
Список входных параметров:
* Количество РЦ компании в России;
* Количество магазинов «Colgate-Palmolive» в России;
* Объем и распределение продукции по точкам продаж;
* Время грузопереработки на складах (РЦ и региональных);
* Количество транспортных средств;
* Время транспортировки продукции от РЦ;
* Стоимость транспортировки продукции
Задачи:
* Построить модель цепи поставок компании «Colgate-Palmolive» в России;
* Оценить эффективность цепи поставок «as is»: насколько экономически эффективна работа одного РЦ при большом количестве точек продаж, расположенных по всей стране;
* Построить модель цепи поставок «to be»: приобретение (аренды) компанией еще одного склада (Новосибирск);
* Сравнить экономические показатели построенных моделей цепи поставок при одном РЦ (централизованная система) и при двух РЦ (децентрализованная);
* Дать рекомендации по дальнейшему функционированию цепи поставок.
По таблице потребления можно сделать приблизительнцые потоки движения в модели

Следует учесть

СТРАННЫЕ ФАНТАЗИИ
В ходе данной работы предполагается рассмотреть, как изменится структура транспортных издержек на дистрибуцию товаров по России, если компанией будет приобретен (арендован) еще один склад. При этом планируется снизить количество транспортных средств, задействованных в доставке продукции до точек продаж
1. Консолидация товара, поступающего со всех производственных площадок, на центральном складе – распределительном центре (РЦ) и грузопереработка.
2. Транспортировка либо напрямую клиентам и дистрибьюторам, либо на региональные склады и кросс-докинг площадку в СПБ, где сразу после прибытия фуры товары перегружаются в более мелкие автомобили и отправляются клиентам.
Консолидация товара, поступающего со всех производственных площадок, на центральном складе – распределительном центре (РЦ) и грузопереработка.
На приемку товара уходит в среднем 24-36 часов
Данные взяты из кейса компании «Colgate-Palmolive», предоставленного ВШЭ.

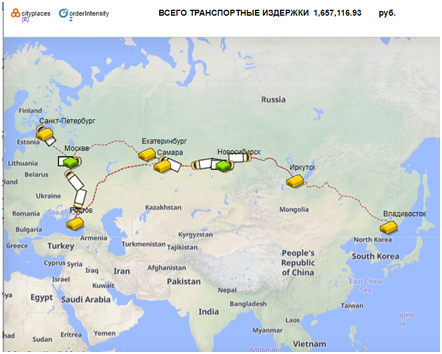
Пояснения по разработке модели
Привязал склады и РЦ к городам России с помощью ГИС поиска
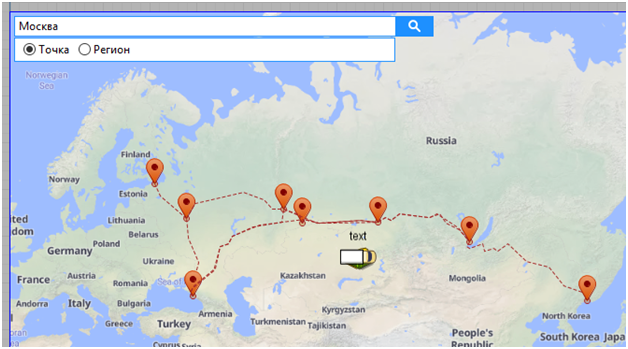
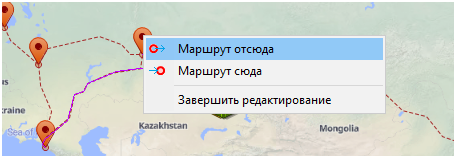
Связал добавленные точки маршрутами
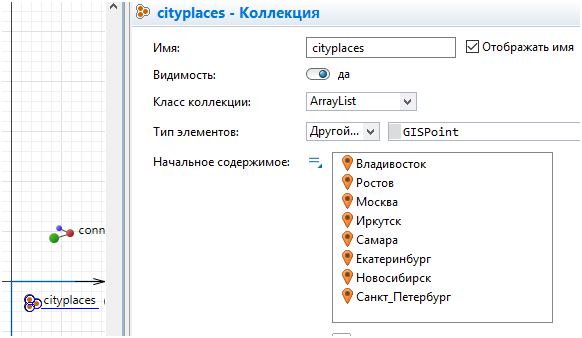
На основе размещенной информации создал коллекцию из городов
Добавил популяцию городов (совокупность агентов типа City)

Связал cities с cityplaces c помощью свойств

Добавил массив спроса(в процентах) для разных городов 

Затраты на транспортировку хранятся в параметре cost (по умолчанию 1435р./час)
Для перемещения товаров по заказам используется популяция грузовиков trucks. Подсчёт затраченных часов на транспортировку ведется следующим образом. В типе агентов есть стрейтчарт 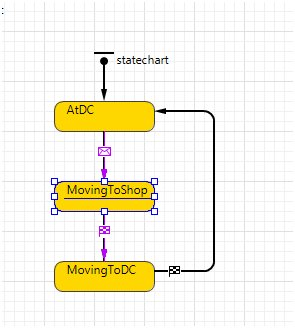
К некоторым состояниям привязаны моменты отсчёта времени начала и конца транспортировки. Это состояния MovingToShop и MovingToDC
Для этого используется код в действиях их свойств
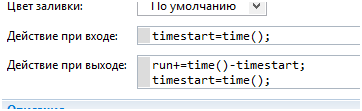
Общая сумма затраченного времени одного грузовика накапливается в переменной этого же класса 
Для подсчета затраченного времени всех грузовиков используется свойство популяции грузовиков 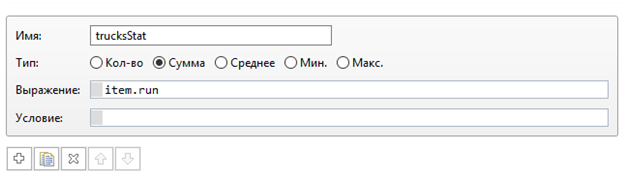
Поле выражение содержит переменную run, о которой я писал выше. Засчёт стандартного функционала Anylogic в популяции возможно автоматическое суммирование переменной run каждого грузовика. Эту сумму можно получить, обратившись к функции популяции trucks по имени trucksStat()
Trucks. trucksStat()
Что и сделано в динамическом значении текста вывода транспортных затрат
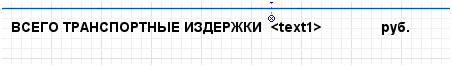

Для регулирования интенсивности поступления заказов в модель добавлен параметр

I)Входной параметр
Связан с интенсивностью появления заказов от клиентов

От этого значения зависит, как часто срабатывает таймер создания заказов внутри типа агента City
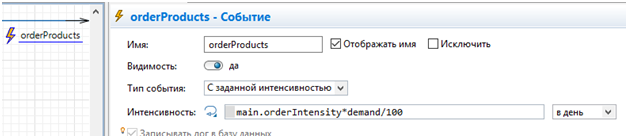
И зависит от величины спроса в том или ином городе demand (в процентах)
II)Входной Параметр

Связан с
От этого значения зависит, как быстро грузовик поедет выполнять заказ

Рис. Statechart типа агента Truck